深入理解ElasticSearch—查询DSL进阶
本文共 863 字,大约阅读时间需要 2 分钟。
一、Apache Lucene默认的评分公式
1、文档匹配需要考虑一下因子
- 文档权重
- 字段权重
- 协调因子
- 逆文档频率
- 长度范数
- 词频
- 查询范数
2、TF/IDF评分公式

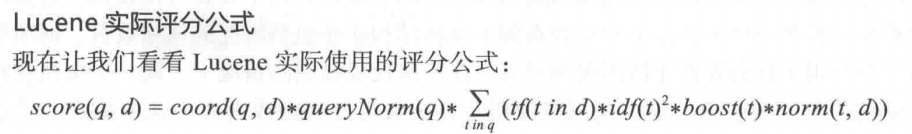
从上面的公式可以导出以下规则:
- 越多罕见的词项被匹配上低分越高
- 文档字段越短(包含更少的词项),文档得分越高
- 权重越高(不论是索引期还是查询期赋予的权重值),得分越高
3、es对lucene评分的使用
es使用了lucene的评分功能,但又不仅局限于lucene的评分功能,用户可以根据不同的查询类型以精确控制文档评分的计算(如custom_boost_factor查询,constant_score查询,custom_score查询等),还可以使用脚本(scripting)来改变得分,也可以使用二次评分功能重新计算得分。
二、查询改写
1、前缀查询
查询所有name字段以字母j开头的文档

改写后等效于:
常数得分查询

2、查询改写属性
rewrite属性配置:
- scoring_boolean
- constant_score_boolean
- constant_score_filter
- top_terms_N
- top_terms_boost_N
三、二次评分
1、含义
重新计算查询返回文档中指定个数文档的得分。
2、示例

该recore得分将每个文档的得分改写成该文档中year字段对应的值,文档得分等于两次查询文档的得分之和。
3、二次评分的参数配置
- window_size
- query_weight
- rescore_query_weight
- recore_mode
四、批量操作
1、批量取


2、批量查询

五、排序
1、简单排序、多值排序

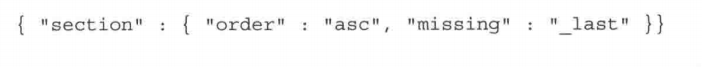


2、基于geo字段排序
查找特定国家离自己最近的一个机构
使用映射:



mode可选max min avg
3、基于嵌套对象的排序

六、数据更新API
1、简单更新

2、使用脚本按条件更新

3、使用更新API创建或删除文档

七、使用过滤器优化查询
1、过滤器与缓存
过滤器是很好的缓存候选方案,及过滤器缓存:





转载地址:http://kflii.baihongyu.com/
你可能感兴趣的文章
太赞了!GitHub 标星 2.4k+,《可解释机器学习》中文版正式开放!
查看>>
程序员用 AI 修复百年前的老北京视频后,火了!
查看>>
漫话:为什么你下载小电影的时候进度总是卡在 99% 就不动了?
查看>>
我去!原来大神都是这样玩转「多线程与高并发」的...
查看>>
当你无聊时,可以玩玩 GitHub 上这个开源项目...
查看>>
B 站爆红的数学视频,竟是用这个 Python 开源项目做的!
查看>>
安利 10 个让你爽到爆的 IDEA 必备插件!
查看>>
自学编程的八大误区!克服它!
查看>>
GitHub 上的一个开源项目,可快速生成一款属于自己的手写字体!
查看>>
早知道这些免费 API,我就可以不用到处爬数据了!
查看>>
Java各种集合类的合并(数组、List、Set、Map)
查看>>
JS中各种数组遍历方式的性能对比
查看>>
Mysql复制表以及复制数据库
查看>>
进程管理(一)
查看>>
linux 内核—进程的地址空间(1)
查看>>
存储器管理(二)
查看>>
开局一张图,学一学项目管理神器Maven!
查看>>
Android中的Binder(二)
查看>>
Framework之View的工作原理(一)
查看>>
Web应用架构
查看>>